 | XML Repository of Irish Legislation (Custom schema) |
 | Linux HowTo's (Docbook) |
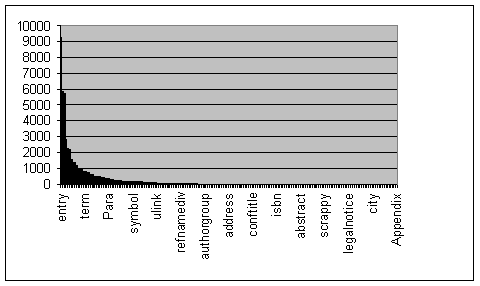 | Postgres Manuals (Docbook) |
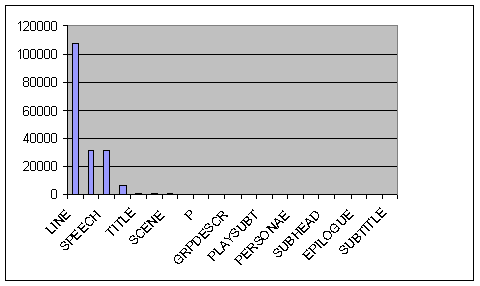 | Shakespeare's Plays (custom schema). |
They are all basically power
law distributions. Take a bow Mssrs Zipf and Pareto. Given that
the data sets underneath are wildly different in shape, size and
subject matter, the similarity in the graphs is striking.
The graphs are produced by charting element types against frequency of occurence.
I have been generating such graphs from SGML/XML datasets for years
and they always take the same general shape. I call it tag share analysis.
Takeaway
- Always do a tag-share analysis before writing an XML
up/down/cross-translate in XSLT or DOM/SAX or whatever. A remarkably small number of element types make up the bulk of the markup - regardless of the size of the schema.